Kumpulan source code pembuatan kartun dan webtoon : https://drive.google.com/drive/folders/1BGakta2lyz0DyLTQCYznuuZoEjqBEZJm?fbclid=IwAR1S_hRnWimg6KdGTDaEOaocdwYRCYOGucS1hFIAEx7kjSr7yVNT0WCG6dA
empo hari saya di kantor dihadapkan pada suatu isu lagging pada salah satu aplikasi yang di kembangkan di kantor saya. Kebetulan yang menemukan isu lagging tersebut merupakan akun yang memiliki banyak data yang harus diambil dari API, yang kemudian diproses di aplikasi mobile (Android atau iOS).
Dengan petunjuk yang memiliki banyak data, maka saya harus
mensimulasikan seperti kasus di atas. Sebenernya ada beberapa cara untuk
mengenerate data untuk kebutuhan testing, misalnya :
Membuat script khusus untuk generate banyak data (bisa menggunakan bahasa pemrograman tertentu atau scripting menggunakan bash script).
Menggunakan Tools Automation Testing seperti Katalon Studio,Tool tersebut dapat melakukan otomasi tes pada beberapa platform seperti, API, Web, dan Mobile.
Postman Collection Runner, nah ini yang akan dibahas pada artikel ini. Jadi penjelasannya di bawah ya
Untuk tata cara pemasangan postman, bisa dilihat di sini. Fitur bawaan postman cukup lengkap, mulai dari Mocking API sampai membuat dokumentasi API juga tersedia.
Fitur-fitur bawaan dari postman
Beberapa fitur yang sering saya gunakan di postman :
Environment dan Global variabel.
Generate code snippets berdasarkan request tertentu.
Membuat Collection, untuk mempermudah mengatur beberapa request dijadikan dalam satu folder tertentu.
Export/Import atau SharingCollection.
Collection Runner dan Scripting
Postman memungkinkan untuk membuat value suatu variabel bisa diset dengan beberapa cara :
Menggunakan Environment dan Global variabel.
Mendefinisikan variabel pada Pre-request Script menggunakan javascript.
Data files, CSV file ataupun JSON file.
Artinya, kita dapat melakukan beberapa skenario tes seperti, generate banyak data maupun melakukan insert banyak data ke database menggunakan API melalui postman.
Mari kita praktikan satu persatu, tiga cara di atas.
1. Menggunakan Environment dan Global variabel
Kita dapat menuliskan suatu variabel dengan format {{nama_variabel}} pada text field yang ada di postman seperti Body, Headers atau params.
Klik Manage Environment
Kemudian klik Add
Isi nama Environment dan variabel yang ingin disetklik dropdownNo Environment …… dan ubah sesuai nama Environment yang diinginkan, kemdudian variabelnya dapat dipanggil seperti di value yang dikasih kotak kuning
Cara di atas hanya untuk menset variabel sekali dan bisa diperbaharui, cocok untuk melakukan setting environment variabel ataupun global variabel yang bersifat tetap. Nah, berarti kita tidak bisa mengenerate banyak data dengan menggunakan cara ini, karena value dari variabelnya hanya diset di awal saja.
Bagaimana cara untuk mengenerate banyak data akan terjawab pada dua poin selanjutnya.
2. Mendefinisikan variabel pada Pre-request Script menggunakan javascript
Ada beberapa snippets yang disediakan :
pm.globals.get("variable_key"); //untuk mengambil variabel global
pm.variables.get("variable_key"); //mengambil variabel lokal
pm.environment.set("variable_key", "variable_value"); //setting environment variabel
pm.globals.set("variable_key", "variable_value"); //setting variabel global
pm.environment.unset("variable_key"); //hapus environment variabel
pm.globals.unset("variable_key"); //hapus variabel global
// melakukan request ke suatu API
pm.sendRequest("https://postman-echo.com/get", function (err, response) {
kemudian, kita dapat memanggil variabel yg telah dibuat di pre-request script tadi.
Selanjutnya, untuk dapat melakukan multiple request masuk pada menu Runner
Pilih collection, kemudian pilih Environment, masukan jumlah iterasinya, masukan delaynya juga berapa, atau langsung default 0, kemudian klik tombol biru Run user generator
Tampilan Runnernya seperti berikut.
3. Data files, CSV file ataupun JSON file
Di sini hanya mencoba CSV file saja, untuk yg JSON file, bisa dicoba sendiri.
Siapkan CSV file, di sini untuk generate data user misalnya.
Misal kita punya data seperti ini
Pada tampilan Runner kita set seperti melakukan dengan pre-request script, namun kita milih datanya dari CSV file.
Kesimpulan
Penggunaan Postman Collection Runner sangat membantu untuk
kebutuhan testing berbagai skenario, dengan data set yang bisa
didefinisikan sendiri menggunakan data CSV file dan JSON file atau
membuat scriptpre-request.
Selamat Mencoba, dan semoga bermanfaat.
Sumber : https://ajaro.id/blog/2018/12/27/mengenal-postman-collection-runner/?fbclid=IwAR0nTl3QmqugcjpBKoWJdbYaxvh6svs8CYJHluKvmSnOoUspwFW3Lp1-EuU#more-223
Pembahasan
tentang literatur animasi pada blog ini admin rasa telah cukup lumayan
banyak macamnya. Pada kesempatan kali ini admin akan berbagi sebuah
source code masih tentang sebuah animasi, yaitu animasi form show baik
dari tengah, pinggir kanan, pinggir kiri, atas dan bawah. Pada saat
button diklik maka akan menampilkan sebuah shape berbentuk kotak yang
berjalan sampai kemunculan form tampil.
Cara Membuat Animasi Form Show dengan Visual Basic 6.0
Bagi yang ingin
mencoba mempelajari admin persilahkan untuk mendownload pada link
download yang tersedia diatas. Semoga bermanfaat dan terima kasih banyak
atas kunjungannya.
Sumber : https://carakuvb6.blogspot.com/2018/12/cara-membuat-animasi-form-show-dengan-visual-basic.html?fbclid=IwAR2rN3IYLesNhff5Uo7d-a_Rr9HLaWKJIslspuXvJyRAAz58mYw_s3r4zx8
Mumpung libur, belajar konsep Docker via video yuk!
Hai, tahukah kamu developer zaman sekarang mulai menerapkan continuous integration / continuous delivery (CI/CD) dalam metode pengembangan aplikasi mereka.
Dari sisi bisnis metode continuous integration ini memang diperlukan
agar bisnis dapat terus beradaptasi dengan kebutuhan yang dinamis.
Nah jika demikian biasanya tim developer yang dibuat pusing jika mereka
harus terus-terusan melakukan delivery secara manual. Makanya kan ga
lucu kalo mereka ga pakai CI/CD.
Nah apakah kamu tertarik untuk
menerapkannya juga? Jika iya, langkah pertama yang bisa kamu lakukan
adalah dengan mempelajari Docker, wah apa itu? saya yakin sebagian sudah
pernah dengan meskipun belum tentu semua menggunakannya sehari-hari,
padahal Docker ini sangat bermanfaat loh bagi Developer meskipun mereka
belum menerapkan CI/CD, ingin tahu lebih lanjut apa itu Docker dan
kenapa penting bagi web developer?
Yuk simak video series ringkas tentang Docker yang saya buat di youtube, klik pada link di bawah ini untuk menonton: http://bit.ly/docker-concept-series http://bit.ly/docker-concept-series http://bit.ly/docker-concept-series
Total ada 6 Videos yang akan memberikan gambaran tentang Docker, tenang ini cuma pengenalan ga ada pusing-pusing koding dulu.
- Video 1 Apa itu Docker? - Video 2 Kenapa memilih Docker? - Video 3 Apakah saya perlu Docker? - Video 4 Docker image & container - Video 5 Dockerfile & docker-compose - Video 6 Laradock & Portainer
Bekerja secara remote telah menjadi aktivitas bagi 34 persen pekerja di Indonesia pada tahun 2013. Jumlah pekerja remote yang pada tahun 2017 mengalami kenaikan menjadi 64 persen ini pun menunjukkan adanya tuntutan transformasi produktivitas di ranah profesional.
Meski bukan hal asing bagi sebagian pekerja, hingga kini belum banyak karyawan perusahaan yang bisa bekerja secara remote. Tidak dapat dimungkiri bahwa ketersediaan fasilitas kerja turut memengaruhi hal ini. Dalam riset Kantar TNS, hanya 44 persen responden yang mengatakan bahwa perusahaan mereka menggunakan teknologi terbaru agar mereka bekerja efektif.
Sementara di Indonesia, hanya 29 persen karyawan yang mengaku terfasilitasi oleh tempat kerja mereka. Angka tersebut cukup ironis, karena negara ini mendapatkan nilai tertinggi mengenai karyawan yang bekerja secara remote.
Menyoroti pengaruh teknologi dan efektivitas bekerja, transformasi
produktivitas lewat pilihan perangkat kerja perlu menjadi pertimbangan
di tengah tuntutan ranah profesional.
Berbicara tentang komputer untuk bekerja, kita tak bisa
mengesampingkan manfaat perangkat penunjang utama bagi pekerjaan ini.
Sekarang, ada beberapa pilihan perangkat untuk memenuhi kebutuhan kerja,
baik produk konsumen berupa komputer yang ditujukan bagi kalangan umum,
maupun produk bisnis seperti komputer perangkat kerja (workstation).
Terkait perangkat kerja, perusahaan teknologi Intel menemukan bahwa
penggunaan komputer nirkabel telah meningkatkan produktivitas mereka
hingga seratus jam per tahun.
Para pekerja profesional mulai dari engineer
hingga kreator konten membutuhkan perangkat dengan fitur yang mampu
bekerja optimal dalam aktivitas tertentu, seperti manipulasi data dan
memproses grafis. Workstation ini pun hadir untuk menjawab kebutuhan kerja mereka.
Setidaknya, ada beberapa kelebihan pada komputer yang berguna bagi pekerja profesional, seperti:
Melakukan rendering grafik kompleks secara lebih cepat
Mendukung aplikasi yang membutuhkan banyak kinerja prosesor
Menyediakan ruang penyimpanan hingga ukuran terabyte
Menghadirkan perangkat kerja yang reliabel bagi pengguna profesional
Pentingnya memilih perangkat kerja yang tepat
Oleh karena kegunaannya dalam memfasilitasi para profesional di
bidang tertentu, perbedaan di antara komputer di segmen bisnis dan
komputer konsumen terletak pada berbagai komponen di dalamnya. Perangkat keras yang dirancang lebih tahan lama, layanan purna jual yang lebih baik, hingga minimnya jumlah bloatware–perangkat lunak tambahan yang kurang penting.
Secara lebih khusus, inilah beberapa komponen teknologi yang dapat kamu temukan dalam komputer produk bisnis:
Fingerprint reader yang mampu mengamankan data pengguna.
Teknologi yang mengidentifikasi permasalahan dalam perangkat,
contohnya: bunyi tertentu yang akan mengisyaratkan adanya kendala dalam
perangkat.
Kinerja perangkat keras yang mampu meningkatkan produktivitas.
Misalnya: Prosesor generasi terbaru serta memori DDR4 untuk membuka
aplikasi dengan cepat, kartu grafis yang mampu melakukan rendering
secara efisien.
Teknologi rapid charge yang memungkinkan baterai laptop kamu mampu terisi nyaris penuh hanya dalam satu jam pengisian.
Baterai yang tahan lama untuk mendukung produktivitas, baik di dalam maupun di luar ruangan.
Material yang teruji dan reliabel, seperti serat karbon serta desain rangka (chassis) yang menjaga perangkat tetap mampu digunakan meski telah jatuh, terhantam keras, maupun terkena tumpahan air minum.
Sampai di sini, kamu mungkin mulai menyadari kendala apa yang
dialami oleh banyak pekerja profesional di luar sana. Ya, sebagian
profesional tersebut harus bekerja dengan perangkat komputer yang kurang optimal untuk menyelesaikan pekerjaan mereka. Akibatnya, produktivitas mereka pun bergantung pada perangkat komputer dari kantor.
Menurut spesialis HR di perusahaan Fortune 500, Steve Wang, fasilitas teknologi yang tepat akan membangunpengalaman positif bagi para karyawan. Sejalan dengan hal ini, 78 persen pekerja menganggap pengalaman kerja yang positif sebagai faktor yang penting.
Apakah perangkat kerja khusus bisa menjadi investasi bagi perusahaan?
Studi Gartner Research terhadap 177 bisnis menemukan bahwa rata-rata usia pakai komputer desktop adalah 43 bulan dan 36 bulan untuk komputer portable.
Dalam riset yang sama, lebih dari sepertiga responden menyatakan bahwa
alasan utama mereka mengganti komputer adalah untuk meningkatkan
produktivitas karyawan. Sementara, lebih dari seperempatnya menyatakan
bahwa biaya perawatan meningkat seiring dengan mesin komputer yang lebih
tua.
Deloitte dalam dokumennya terkait tempat kerja di era digital,
menyebutkan bahwa penyediaan perangkat kerja yang tepat mampu
meningkatkan pengalaman karyawan dan turut memengaruhi kinerja mereka.
Lebih lanjut, perangkat teknologi yang mampu menunjang kinerja akan
menghemat waktu kerja hingga 43 menit tiap bulan.
Setelah kamu mengetahui perbedaan produk komputer bisnis dan komputer konsumen, kamu bisa mulai merencanakan tipe perangkat mana yang sesuai untuk
bisnis kamu. Ada beberapa alternatif untuk mengupayakan transformasi
produktivitas melalui perangkat teknologi, baik komputer desktop maupun komputer portable.
Namun, kamu perlu mengingat bahwa jumlah angkatan kerja yang berasal dari generasi milenial di Indonesia telah mencapai 62,5 juta orang pada tahun 2016. Dalam studi Dale Carnegie Indonesia tentang Employee Engagement Among Millennials, hanya 25% tenaga kerja milenial yang sepenuhnya terlibat dengan perusahaan mereka.
Sebagaimana diperbincangkan dalam banyak diskusi, generasi milenial cenderung menyukai jam kerja yang fleksibel dan memungkinkan mereka bekerja remote.
Di sinilah perusahaan berpeluang meningkatkan keterlibatan dan
produktivitas karyawan mereka. Salah satunya, lewat perangkat kerja portable yang mendukung mereka untuk bekerja dari mana saja, seperti produk seri Thinkpad milik Lenovo yang didukung Windows 10 Pro. Beragam fitur yang diperlukan oleh pekerja di berbagai ranah industri, tersedia dalam seri jenama produk teknologi ini.
Ingin tahu lebih jauh bagaimana cara milenial mendefinisikan
produktivitas di tempat kerja mereka? Pelajari transformasi
produktivitas dengan perangkat teknologi yang tepat di sini!
Sumber : https://id.techinasia.com/bagaimana-teknologi-yang-tepat-memengaruhi-produktivitas-pekerja?fbclid=IwAR3tieLuWukyJcbsP6SfesZhWW6U1N0WsJP-S8tluj-3FXY241-E_UMRuys
Dalam beberapa situasi seorang web developer ingin mengonlinekan atau
mengekspos local server (localhost) ke internet dengan tujuan untuk
memperlihatkan aplikasi web yang sedang dikembangkan ke client secara
cepat saat itu juga. Contoh lain seorang mahasiswa ingin mendemokan
tugas akhir aplikasi web yang ia kerjakan dan diminta oleh dosen agar
aplikasi web tersebut dapat diakses di internet pada saat ujian. Upload
web ke web hosting membutuhkan waktu lagi ditambah harus export import
database, dan mahasiswa pada umumnya belum memiliki akun web hosting.
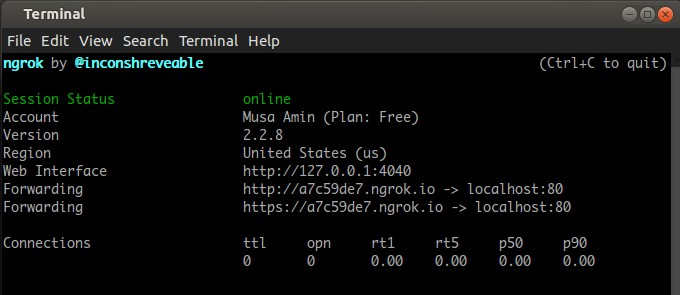
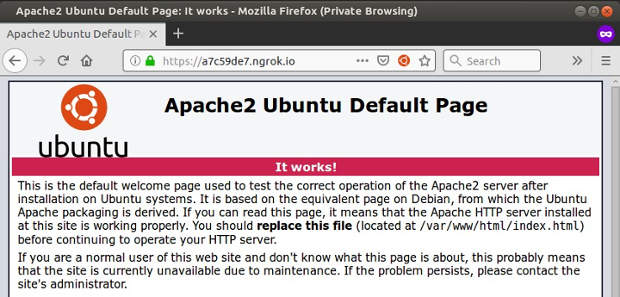
Bagi web developer yang memiliki VPS dapat dengan mudah mengekspos local server ke internet dengan melakukan SSH Remote Port Forwarding. Nah, bagaimana yang belum memiliki VPS atau SSH server? Untuk masalah ini kita bisa menggunakan layanan dari ngrok.com. Ngrok akan membuat tunnel antara local server dengan Ngrok server. Ngrok mendukung sistem operasi macOS, Windows, Linux, dan FreeBSD. Ngrok hanya satu file binary, tidak perlu instalasi paket lain. Ngrok tersedia paket Free dan berbayar.
Contoh : $login = $e->query("select * from user where email='$email' AND password='$password' and (IF(level='$enumList[0]',1,0)OR (level='$enumList[1]')) and status=1");
Sebagai toko online kita sebagai pemilik bisa menambahkan produk yang mau kita jual.dan produk itu kita juga bisa memberikan potongan harga atau diskon.ok di sini saya akan memberi diskon untuk produk di Prestashop.
Latar belakang
Karena untuk membuat pelanggan tertarik pada produk kita salah satu strategi yang di gunakan adalah potongan harga atau diskon.nah untuk itu saya akan beri diskon untuk produk-produk tertentu.
Tujuan
menambahkan potongan harga atau diskon untuk produk di Presatshop
Alat dan bahan
produk-produk yang mau diberikan diskon
Lama pelaksanaan
10 menit
Tahap pelaksanaan
1.ok kali ini saya akan membuat diskon untuk produk yang saya beri garis merah.dan di situ saya akan beri potongan harga 30%.
2.kemudian saya masuk sebagai admin.setelah masuk pilih menu CATALOG>Products
3.setelah itu pilih produk mana yang mau di beri diskon.lalu pilih edit untuk proses pemberian diskon produk.
4.ok pada menu Specific pricespilih menu add a new Specific prices
5. 1. For, digunakan untuk mengatur harga diskon ditujukan untuk siapa saja. 2. Customer, Anda bisa memilih pelanggan yang lebih spesifik dan langsung di atur untuk siapa target diskon anda. Mulailah menulis kata pertama dari pelanggan “first name atau last name” lalu pilih yang akan nda beri diskon. 3. Combination, Anda bisa memilih harga yang spesifik untuk diaplikasikan ke beberapa kombinasi produk, atau hanya satu. Jika anda menginginkan untuk mengaplikasikan lebih dari 1 kombinasi tapi tidak semua produk, anda harus membuat specific price untuk setiap kombinasi. 4. Available from / to, Disini anda bisa mendefinisikan range tanggal aktif dari harga diskon. Klik tiap selection, akan muncul kalender dan pilih range tanggalnya. 5. Starting at, berisi jumlah produk diskon. 6. Produck price ( tax excl) , Tempat dimana anda bisa mengatur arbitrary price. Perhitungan sendiri. Isi angka “0” sebagai default. 7. Leave base price, Centang kotak ini untuk reset “harga product / product price” 8. Apply a discount of, Diskon akan diaplikasikan sekali ketika konsumen memilih jumlah barang. Gunakan selector untuk mengatur tipe diskon.
6.nah sekarang saya sudah memberi diskon 30% untuk produk yang ada pada kotak merah di bawah ini
I would like to share with everyone how we can build a friend recommendation by using some of the capabilities of MaxCompute,
Alibaba Cloud's Big Data computing platform, and finally provide a
demonstration of a social friend recommendation system. Big Data is a
hot topic right now, and if we want to use this data, then we need to
consider three elements.
The first element is massive data. The more data we have, the better.
Only when we have enough data can we tap into the hidden potential of
that data. The second is the ability to process data. We need to have
the ability to quickly process the data we have to find the meaning
hidden within it. The third element is commercialization. When we
collect data, while more is better, that is not the only important
factor. It also has to apply to a specific scenario. In this article, we
will take a recommendation system as an example to see how Big Data
helps in improving these recommendations.
On the left, we have Alipay's friend recommendation system, which is
similar to what you get on other social media platforms such as
LinkedIn. When we open up Alipay, there is a column of recommendations
below showing you people who may be your friends. Generally, the people
in this list are all people that you know and may not have added yet. On
the right, we can see LinkedIn, which is a social networking job search
site. LinkedIn also provides such recommendations. It shows you users
who are potentially your friends and tells you how many degrees of
separation are between you and that user, up to three degrees. LinkedIn
displays highly relevant suggestions directly in front of the user, and
those that are potentially less relevant, it places towards the back.
Both are typical friend recommendations.
So how do you recommend a friend to a user? The relationship between
the two users is initially non-friend, then we have to determine the
common friends between the two. This way we can give the user a
recommendation. For example, if the two users have several common
friends, then we assume that the two users are likely friends, and
that's mostly how the process works.
The right side of the picture is a social relationship service
between people. For example, A and B are friends. We can use five
methods to illustrate that to have a machine analyze this data; we need
to convert the right side of this social relationship to data that a
machine could recognize. This is similar to binary representation on the
left-hand side. For example, A is friends with B, C, and D, so on the
left side, A, B, C, and D have a friends relationship.
This way we can pass this information to the machine for analysis.
For example, once we analyze the data, we may find that A and E have a
common friend, and B and D have two friends in common, while C and E
have one friend in common. Now, we can recommend B and D as potential
friends, and place this recommendation in front. Also, we will put A and
E or C and E towards the back. That is to say, that potential friends
with several friends in common get placed towards the front, while
potential friends with fewer friends in common get placed towards the
back. At least, this is what we want as a result.
Analysis Model for Friend Recommendation Systems
How can we compute such a thing? What method can we typically use? We
can use a computational model like MapReduce. MapReduce is a
programming model used for parallel computing of large-scale datasets.
It consists of three parts: Map, Combine, and Reduce.
Here, we are taking friend recommendation as the example.
Fist input the data on the left that the machine can recognize. After
the input, first split the data on the Map end and split it into two
different datasets. When splitting, convert it to a key, value data
type.
For example, what would the A, B, D, and E lines of data convert to?
The value for A and B would be 0, indicating that the two are already
friends. If the two are not friends, then we need to customize this line
of data so that the value is treated as 1. The values of B and E, and D
and E below are also 1. Convert the original row of data into a key -
value data type as the data on the right similar to the above and below
examples. This is what we do with Map. We split the data based on two
key, values and convert the data into a key, value data type.
The combine operation involves first performing a summary of the
local data where we see which of the data is redundant. For example, if
the value of A and B is 0, and the value of B and A is also 0; the same
relationship is represented twice. Hence, we need to save only one piece
of data. Similarly, I have used this method to summarize the data
locally, as shown in this image with these two data.
The third step is the Reduce phase. The goal of Reduce is to
summarize this data, that is to summarize the data on both side
together, then summarize the unique value corresponding to each key.
This is the final computation result. If the two users are already
friends and the value is zero, then there is no need to make the
recommendation. Therefore, if A and B are zero, then they will be
deleted. We only need to know that the value is greater than zero and
there are potential friends. At the same time, the two individuals are
still not friends, so we have achieved the desired result.
Friend Recommendation Systems on Alibaba Cloud
How do we build the architecture of a friend recommendation system on
Alibaba Cloud? For example, there is social software that is also a
business system. The front end uses Alibaba Cloud's cloud server ECS to
deploy the entire social software application. We can save the data
input to Alibaba Cloud's ApsaraDB for RDS
database service. This is the current social networking application
system. The business system produces a data entry; so we have to know
how to analyze the data.
First, we need to extract the data from the database to Alibaba Cloud's big computation service MaxCompute.
This is very similar to our traditional ETL digital warehouse. The
process uses Alibaba Cloud's Big Data development platform to analyze
and process the data.
Using this, we can quickly and easily develop processes such as data
seeding or data generation. This employs a Big Data development platform
and Big Data manufacturing. The result is a data analysis result, but
it also requires the front-end application to analyze and display the
results.
Technical Features of MaxCompute
The main technical points to MaxCompute are as follows:
Distributed: distributed cluster, cross-cluster technology, and flexible scalability.
Secure: from a security standpoint, it features automatic storage error correction, sandbox mechanism, and multiple backups.
Easy to use: it has a standard API, full SQL support, upload and download tools.
Permissions control: multi-tenant management, user rights policy, data access policy.
Use Cases of MaxCompute
You can use MaxCompute to build your data warehouse. At the same
time, MaxCompute can also provide a kind of distributed application
system. For example, you can use map calculations, or an effective wide
format to create an appropriate workflow. As data analysis does not
involve just analyzing data once; instead, the process is cyclic. For
daily analysis of data, you can create a workflow for such a task in
MaxCompute, then set a periodic schedule that runs the task once every
day.
MaxCompute can call the periodic task according to the set workflow.
MaxCompute is also useful for machine learning because machine learning
can also use the data analyzed by MaxCompute. If other similar services
perform data analysis, then you can place the result on a machine
learning platform, where the machine calculates a model to learn the
data and produce the model you want.
Alibaba Cloud DataWorks
Another addition to MaxCompute is Alibaba Cloud's Big Data development environment, DataWorks (formerly DataIDE).
DataWorks provides an efficient and secure offline data development
environment. DataWorks is only a development of the data task workflow,
while MaxCompute handles the underlying data processing and data
analysis tasks. In other words, DataWorks is an image of the data
development service, which helps us in making better use of MaxCompute.
Moreover, we can develop in DataWorks and do not need to develop right
in MaxCompute. The results of developing in MaxCompute are incomparable
to those of developing in DataWorks.
The image above represents a use case of the entire DataWorks
application. When we perform data analysis, first, we need to integrate
the original data, which we can accomplish in DataWorks. We have to take
all of the information for the original data and save it on MaxCompute.
We can also use DataWorks for post processing, saving, and other
operations. DataWorks can handle data storage, analysis, processing,
clustering, etc. during the entire data analysis process.
MaxCompute Application Development Process
The MaxCompute application development process is made up following six steps:
Install a configuration environment
Develop an MR program
Test scripts in local mode
Import JAR packages
Upload to the MaxCompute project space
Use MR on MaxCompute
Here, we will explain this process in detail using friend
recommendation as an example. First, we need to install the MaxCompute
client. Its benefit is that we can use the terminal locally to use
Alibaba Cloud MaxCompute remotely. Locally, we only have to set the
MaxCompute information. Also, we need to configure our own development
environment, since Alibaba Cloud's MaxCompute mainly supports two
languages; Java and Eclipse. Then we create a new project. On creating a
new project, we would find a read envelope. The red envelope contains
the information that we need to configure the local client. Now we enter
the code writing phase.
The next step is simple testing. Testing after development allows us
to ensure that the code is working correctly. The input here is test
data. An output data type is a form with three columns, the first is
User A, the second is User B, and the third is the number of common
friends between them. We only need to take note of the first three, and
then perform testing.
Next, we need to run the data code locally. The result of this run is
the local development test. When testing locally, there is data here.
Your first step is to choose which project to process. The second step
is to select the input and output tables. You also need to specify the
output table, the goal of the output table, and save the output results
inside. Once the configuration is set, click run and get the result.
After a successful local development test, we need to pack it into a
JAR package, then upload it to Alibaba Cloud, that is to the MaxCompute
cluster. Once the second has been packed into a JAR, add the resources.
Below, we take the JAR and use resource management to upload the JAR.
This concludes the upload of locally developed and tested MR package to
the MaxCompute cluster.
Once you have uploaded it, you can use it to create a new task, then
give the task a name and indicate to which JAR the task correlates. Next
is OPENBMR. As we have selected the MR process, so we have to select
the OPENMR module inside. To generate this kind of task, we go to the
edit page and then pass instructions that when it receives an OPENMR
task, it needs to use the friend recommender JAR, and at the bottom
instruct it to use the program logic in the JAR. Once these settings are
complete, we can click run to get the results. This is our local
development test. We upload the resource to the MaxCompute cluster, then
use the JAR we developed locally on the cluster. This is the entire
development and deployment process.
Read similar articles and learn more about Alibaba Cloud's products and solutions at www.alibabacloud.com/blog.
Sumber : https://www.alibabacloud.com/blog/building-a-social-recommendation-system-based-on-big-data_593980?utm_content=m_1000017072
1. Mengenal Istilah Structured Data, Schema Markup & Rich Snippet
Sering kali kita mendengar kata data terstruktur (structured) dan juga Data Tidak Terstruktur (Unstructured).
Data terstruktur adalah data yang berada dalam satu tempat baik berbentuk sebuah file termasuk data yang berada dalam database ataupun spreadsheet. Data terstruktur adalah yang membuat model data. Contohnya adalah data CRM, Industry Research Data dan lain sebagainya.
Data terstruktur biasanya dijalankan untuk mengakses database yang disebut dengan Structured Query Languange atau yang lebih dikenal dengan SQL.
Berikut adalah ilustrasi tentang SQL. Anda ingin melihat daftar buku yang memiliki harga diatas 1000 dan di urutkan sesuai dengan judul, Anda bisa menggunakan.
SELECT * FROM buku WHERE harga > 1000 ORDER BY judul;
Dari sana Anda akan mendapatkan data dari database sesuai permintaan Anda dengan memunculkan buku yang memiliki harga diatas 1000 dan otomatis diurutkan sesuai judul.
Sedangkan Data tidak terstruktur adalah data yang tidak mudah diklasifikasi dan dimasukan kedalam sebuah kotak dengan rapi. Contohnya adalah foto, gambar, grafis, streaming, instrument data, webpages, pdf, konten blog dan lain sebagainya.
Salah satu aspek yang membuat mesin pencari sepertiGoogle Searchbisa akurat adalah tersedianya data yang terstuktur di halaman web.Semakin terstruktur semakin baik Google menilai suatu halaman web, karena artinya pemilik situs serius dalam menyediakan content yang baik.
Schema Markup adalah suatu bentuk microdata yang digunakan untuk menanamkan metadata HTML terstruktur (“data tentang data”) dengan konten halaman web yang ada untuk memberikan informasi tambahan serta pengalaman browsing yang lebih kaya bagi pengguna atau dapat kita kenal dengan istilahRich Snippets.
Dalam upayanya, HTML, Google, Microsoft, Yahoo dan sekarang Yandex telah bersama-sama menciptakan Schema Markup umum. Hasil kerja kolektif mereka adalah situsschema.org, yang memiliki tujuan menciptakan Schema Markup yang seragam atau memiliki standar yang saling didukung oleh semua search engine.
Meskipun belum diakui secara resmi dampak positif yang diberikan dari Schema Markup pada SERPs (peringkat halaman di search engine),Searchmetricsmenemukan bahwa halaman dengan integrasi schema.org berperingkat lebih baik dengan rata-rata empat posisi dibandingkan dengan halaman tanpa schema.org.
Informasi-informasi tambahan dari hasil pencarian akan membuat daftar terlihat lebih dalam pencarian, yang berarti akan lebih banyak traffic organik untuk blog WordPress anda. Tentunya hal ini akan membantu dalam membangun sebuah otoritas pada niche yang anda pilih menjadi blog yang terlihat lebih dalam hal pencarian.
“Secara umum, semakin banyak markup yang ada, seperti skema, video atau apa pun, semakin mudah search engine menafsirkan apa yang benar-benar penting pada sebuah halaman,” kata Matt Cutts, kepala tim spam web Google.
Schema Markup memberikan win-win solution bagi ketiga pihak:
Search engine, yang harus terus menerus meningkatkan pengalaman pengguna untuk menjaga / meningkatkan pangsa pasar pencarian mereka,
Pengguna/user, yang menerima hasil pencarian yang lebih baik, dan
Pemilik website, yang memanfaatkan Schema Markup sebagai senjata mutakhir SEO.
2. Memasang Schema Markup Pada WordPress Menggunakan Plugin
Mengelola Schema Markup secara manual bisa menjadi hal sulit bahkan bagi pemilik situs berpengalaman. Untungnya, ada beberapa pluginWordPressyang akan menjadikannya sangat mudah bagi anda untuk menambahkan Rich Snippets di situs WordPress.
Ada beberapa pilihan plugin yang dapat kita gunakan :
a. Hal pertama yang perlu anda lakukan adalah menginstal dan mengaktifkan pluginAll In One Schema.org Rich Snippets. Setelah selesai instalasi, lakukan aktivasi cukup dengan meng-klik pada ikon menu Rich Snippets pada sidebar untuk melanjutkan.
Akan terlihat jenis konten yang berbeda yang dapat dibuat dengan plugin ini. Berikut adalah daftar cakupan jenis kontennya:
Item Review
Events
Person
Product
Recipe
SoftwareApp
Video
Article
b. Yang perlu anda lakukan adalah dengan membuat posting baru atau mengedit postingan yang sudah ada. Tepat berada di bagian bawah post editor, akan telihat meta kotak baru yang berlabel Configure Rich Snippets. Di dalamnya akan terlihat menu drop-down yang dapat memilih jenis konten untuk posting yang sedang di kerjakan.
c. Setelah memilih jenis konten maka akan menampilkan field Rich Snippets yang perlu diisi. Pada gambar di bawah, terpilih jenis kontennya adalah artikel, dan itu akan menunjukkan nama artikel, penulis, deskripsi singkat, dan fields dari gambar artikel.
Tidak diharuskan untuk menambahkan semua field tetapi beberapa field yang hanya diperlukan oleh Google untuk menampilkan Rich Snippets saja. Dan jangan lupa untuk menyimpan posting ke tempat penyimpanan data dari Rich Snippets.
3. Memasang Schema Markup Pada WordPress Menggunakan Cara Manual
Rich Snippets atau Schema Markup dapat ditulis dalam format yang berbeda diantaranya adalahMicrodata,RDFa, danJSON-LD. Anda dapat menggunakan salah satunya di situs anda.
Apabila menambahkan Rich Snippets secara manual ke dalam postingan WordPress, maka diperlukan juga dokumentasi rujukan keGoogle’s Developer Resource on Structured Data dan Schema.orguntuk memahami sifat-sifat yang diperlukan untuk masing-masing jenis kontennya.
Berikut contoh menambahkan Schema Markup pada Tag HTML menggunakan format microdata:
<p>
<a href="http://npr.org">National Public Radio</a> has a sponsor:
<a href="http://www.example.com/GloboCorp">GloboCorp</a>.
</p>
berubah menjadi:
<p itemscope itemprop="organization" itemtype="http://schema.org/Organization">
<a href="http://npr.org" itemprop="url">
<span itemprop="name">National Public Radio</span>
</a> has a sponsor: <span itemprop="sponsor" itemscope itemtype="http://schema.org/Organization">
<a itemprop="url" href="http://www.example.com/GloboCorp">
<span itemprop="name">GloboCorp</span>
</a>
</span>.
</p>
Berikut contoh penggunaan Schema Markup menggunakan Microdata untuk menampilan thumbnail video pada search engine:
Required Properties:
Name
Description
ThumbnailUrl
UploadDate.
<div itemscope itemtype="http://schema.org/VideoObject">
<link itemprop="url" href="http://www.ted.com/talks/boaz_almog_levitates_a_superconductor">
<meta itemprop="name" content="The levitating superconductor" />
<meta itemprop="description" content="How can a super-thin 3-inch disk levitate something 70,000 times its own weight? In a riveting demonstration, Boaz Almog shows how a phenomenon known as quantum locking allows a superconductor disk to float over a magnetic rail — completely frictionlessly and with zero energy loss. Experiment: Prof. Guy Deutscher, Mishael Azoulay, Boaz Almog, of the High Tc Superconductivity Group, School of Physics and Astronomy, Tel Aviv University." />
<meta itemprop="uploadDate" content="2015-02-05T08:00:00+08:00" />
<meta itemprop="duration" content="PT10M25S">
<img itemprop="thumbnailUrl" src="https://tedcdnpi-a.akamaihd.net/r/tedcdnpe-a.akamaihd.net/images/ted/b9693798223a4101be834398af15df5560d3f25c_1600x1200.jpg?quality=95&w=480" />
</div>
Sedangkan contoh Schema Markup menggunakan format JSON-LD:
<p>
<a href="http://npr.org">National Public Radio</a> has a sponsor:
<a href="http://www.example.com/GloboCorp">GloboCorp</a>.
</p>
Perlu diketahui bahwa pada pengimplementasian menggunakan format Microdata, anda perlu untuk melakukan perubahan code HTML yang sudah ada. Sedangkan pada JSON-LD jauh lebih mudah dibaca dan juga di-debug. Ini juga tidak perlu disisipkan dengan teks yang terlihat pengguna dari halaman dan oleh karena itu, ini dapat mempermudah untuk mengekspresikan data Anda.
Berikut adalah contoh jika Anda ingin memberikan informasi tambahan atau Schema Markup Local Business pada situs WordPress Anda, dengan menggunakan format Microdata anda cukup meletakan nya di widget footer.
Dan apabila menggunakan format JSON-LD, Anda bisa meletakkan pada custom field saat Anda berada pada halaman pembuatan artikel baru.
CATATAN:Bagi Anda yang ingin bermain-main dengan Schema Markup tapi takut akan kompleksitas dan tidak begitu familiar dengan HTML, Google telah menciptakanStructured Data Markup Helper.
b. Pilih jenis data yang Anda berencana untuk markup.
c. Paste di URL dari halaman atau artikel yang ingin Anda markup atau Anda juga dapat memasukan HTML pada field yang disediakan. Kemudian, klik “Start Tagging.”
d. Sorot dan pilih jenis elemen yang akan ditandai. Gunakan daftar item data sebagai panduan, dan sorot item lainnya dalam artikel Anda untuk menambahkan mereka ke daftar markup.
e. Setelah selesai, klik “Buat HTML.”
f. Tambahkan Schema Markup ke halaman web Anda sesuai letak perubahan yang ditandai dengan baris kuning.
g. Alternatif sederhana adalah untuk men-download file HTML yang dihasilkan secara otomatis, dan copy / paste ke CMS atau sumber kode Anda.
4. Cara Melakukan Pengujian Schema Markup atau Rich Snippets
Google maupun search engine lainnya mungkin tidak segera mengambil Rich Snippets atau menunjukkannya dalam hasil pencarian. Bagaimana agar bisa tahu cara menggunakan Rich Snippets dengan benar di blog WordPress?
Caranya hanya perlu mengunjungiGoogle’s Structured Data Testing Tooldengan cara menyisipkan markup kedalam tool nox atau klik pada link Fetch URL untuk memasukkan URL. Dan klik pada tombol Validate dan tool akan meninjau markup yang telah disubmit.
Apakah Schema Markup senjata baru SEO? Mungkin bukan; dunia pemasaran digital yang sudah terlalu menyebar dan canggih untuk itu. Namun, jika bisnis Anda mencari strategi SEO baru dan efektif, Schema Markup menawarkan cara yang nyata untuk meningkatkan pengalaman pelanggan dan menenangkan search engine.
Semoga artikel berjudul “Mengenal Schema Markup & Structured Data SEO” bisa bermanfaat dan silahkan jika masih ada yang kurang jelas dapat ditanyakan di kolom komentar dibawah ini.
SilahkanLike FanspagedanShareartikel ini jika menurut kamu bermanfaat untuk kamu dan orang lain.
Sumber : https://informatikalogi.com/mengenal-schema-markup-structured-data-seo/